
GCS ファイルのカスタムメタデータでバッチの処理ステータスを管理してみた。
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、みかみです。
先週お祭りに行ったら、荷台が水槽になってて綺麗な魚が泳いでる美ら海水族館の出張トラックが来てました。
その横は漁協の出店で、お刺身を買ってる人がたくさんいて、ちょっとシュールでした。
やりたいこと
- バッチの処理ステータスを管理したい。
- 別ファイルや他サービスを使うことなく、簡単にバッチ処理ステータスを管理したい。
- GCS ファイルのカスタムメタデータを使って、処理ステータスを管理したい。
前提
GCS の API の有効化と操作に必要な権限は付与済みです。
また、本エントリでは GCS ファイルのカスタムメタデータの利用を目的としているため、ユースケースとして考えている一部の処理(フォーマット変換やデータロードなど)のコード実装は省略し、ログ出力をもって実際の処理が実行されたものとしています。
準備
GCS にファイルをアップロードする、以下の Python スクリプトを用意しました。
import csv
import io
from google.cloud import storage
def upload_csv_to_gcs(bucket_name, destination_blob_name, data, headers):
with io.StringIO() as output:
writer = csv.writer(output)
writer.writerow(headers)
writer.writerows(data)
csv_content = output.getvalue()
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(destination_blob_name)
blob.upload_from_string(csv_content, content_type='text/csv')
print(f"CSV content uploaded to {destination_blob_name} in bucket {bucket_name}.")
def set_blob_metadata(bucket_name, blob_name, metadata):
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(blob_name)
metageneration_match_precondition = None
metageneration_match_precondition = blob.metageneration
blob.metadata = metadata
blob.patch(if_metageneration_match=metageneration_match_precondition)
print(f"The metadata for the blob {blob.name} is {blob.metadata}")
def main():
bucket_name = 'test-mikami'
destination_blob_name = 'export_data/path/file_test.csv'
headers = ['Name', 'Age', 'City']
data = [
['Alice', 30, 'New York'],
['Bob', 25, 'Los Angeles'],
['Charlie', 35, 'Chicago']
]
# ファイルアップロード
upload_csv_to_gcs(bucket_name, destination_blob_name, data, headers)
# メタデータ更新
metadata = {'status': 'uploaded'}
set_blob_metadata(bucket_name, destination_blob_name, metadata)
main()
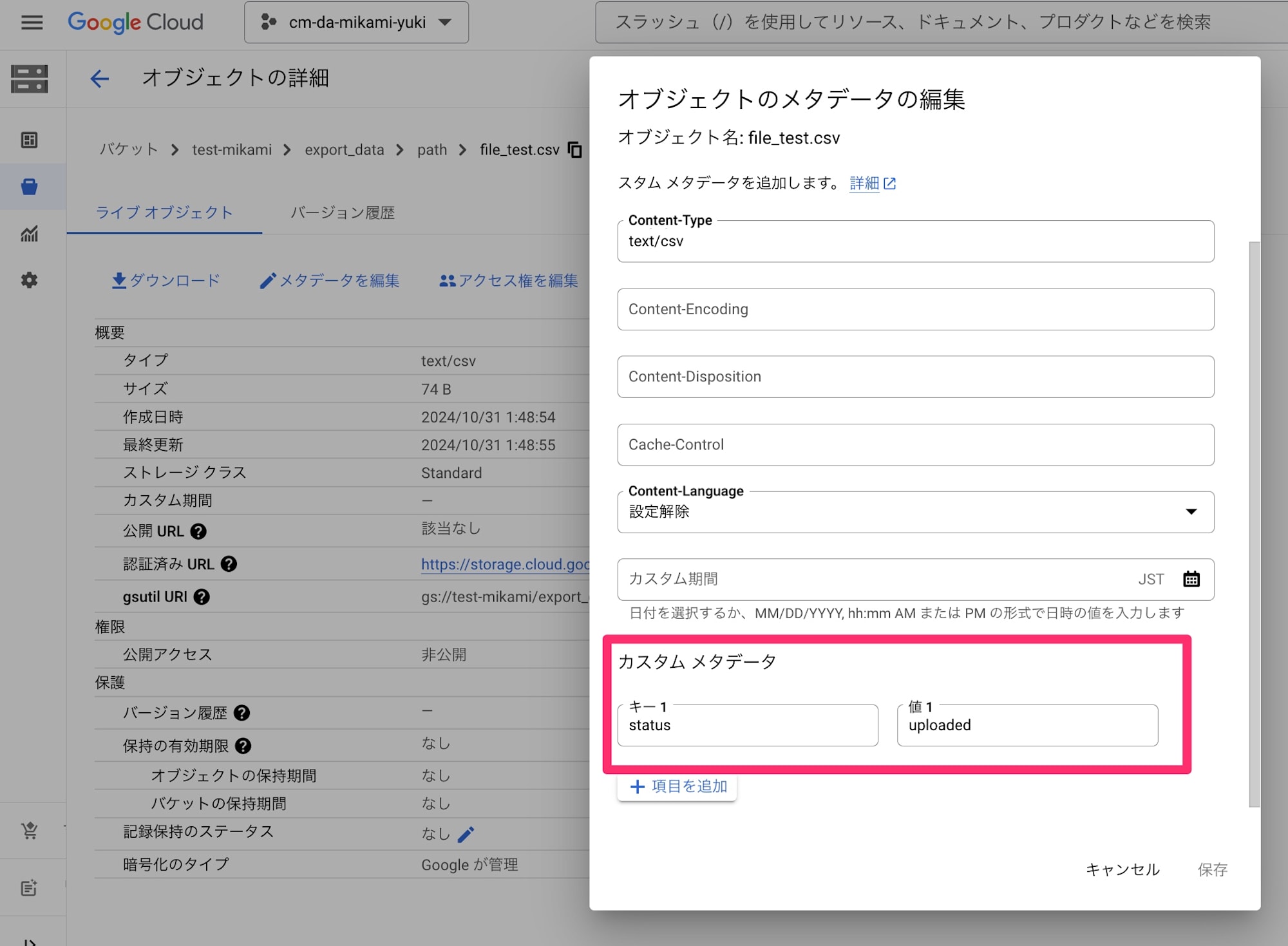
CSV ファイルを GCS にアップロードした後、以下のカスタムメタデータを付与します。
- key: status
- value: uploaded
スクリプト実行して、想定通りメタデータが付与されたファイルが GCS に作成されたことを確認しました。
バッチ処理を考える
以下のような、フォーマット変換処理とデータロード処理を実行するケースを想定してみます。
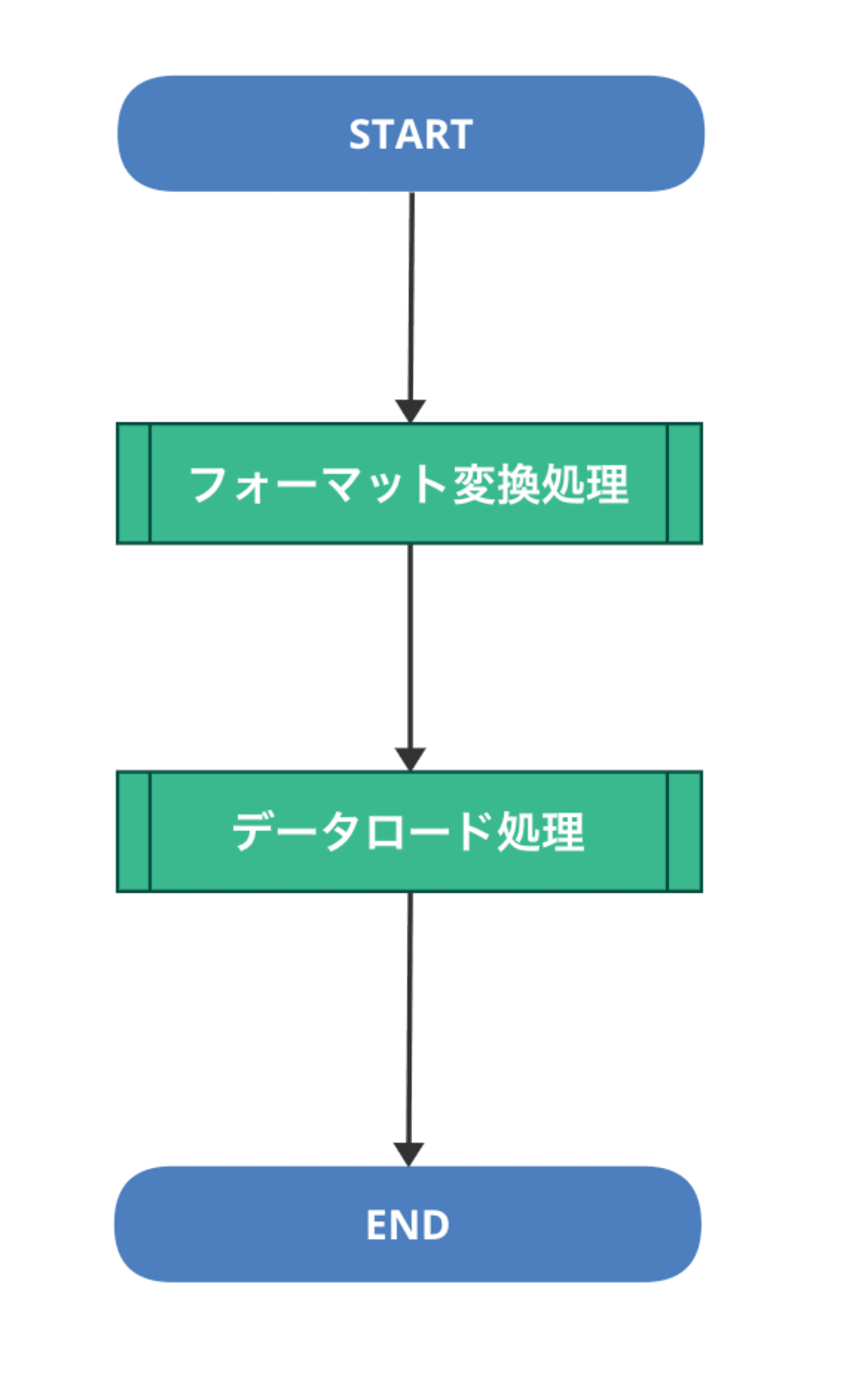
フォーマット変換処理、データロード処理が Cloud Run Functions のような別モジュールとして実装されていて、
それぞれスケジュール実行で起動されるようなイメージです。
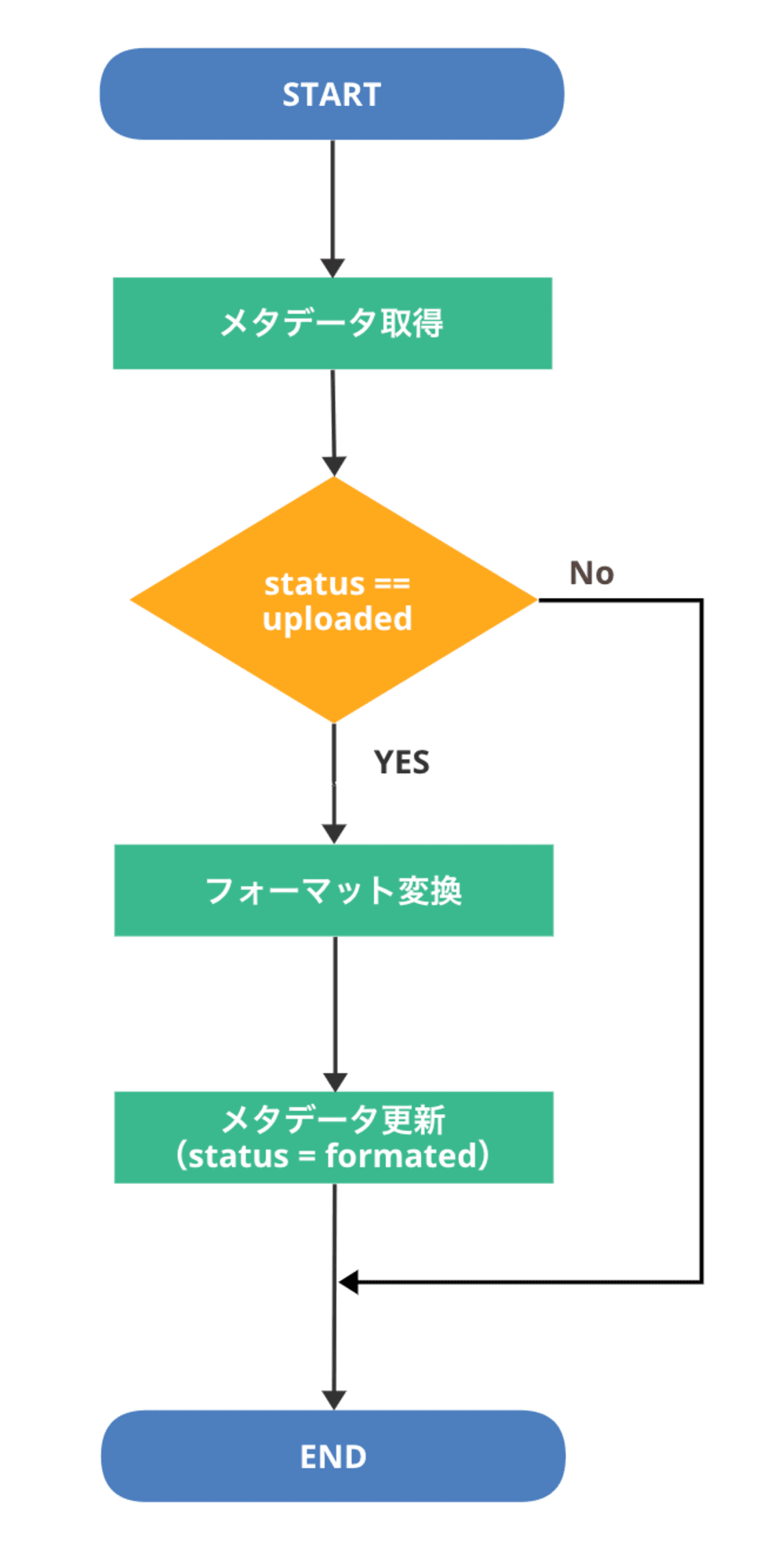
フォーマット変換処理
フォーマット変換処理では、まず対象ファイルのメタデータを取得して、
カスタムメタデータ status の値が uploaded であるかどうか確認します。
status が uploaded でない場合は、まだアップロード処理が完了していない、もしくは処理対象ファイルではないので、処理せず終了します。
以下のコードを作成しました。
from google.cloud import storage
def get_metadata(bucket_name, blob_name):
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(blob_name)
blob.reload()
print(blob.metadata)
return blob.metadata
def is_exec(bucket_name, blob_name):
metadata = get_metadata(bucket_name, blob_name)
status = metadata.get('status')
if status == 'uploaded':
return True
else:
print(f"invalid status: {status}")
return False
def set_blob_metadata(bucket_name, blob_name, metadata):
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(blob_name)
metageneration_match_precondition = None
metageneration_match_precondition = blob.metageneration
blob.metadata = metadata
blob.patch(if_metageneration_match=metageneration_match_precondition)
print(f"The metadata for the blob {blob.name} is {blob.metadata}")
def format_file(bucket_name, blob_name):
print(f"Exec format.")
def main():
bucket_name = 'test-mikami'
blob_name = 'export_data/path/file_test.csv'
# 実行判定
if not is_exec(bucket_name, blob_name):
return
# フォーマット変換処理実行
format_file(bucket_name, blob_name)
# メタデータ更新
metadata = {'status': 'formated'}
set_blob_metadata(bucket_name, blob_name, metadata)
main()
今回は動作確認目的なので、実際にはフォーマット変換処理は行わずにログ出力だけ行います。
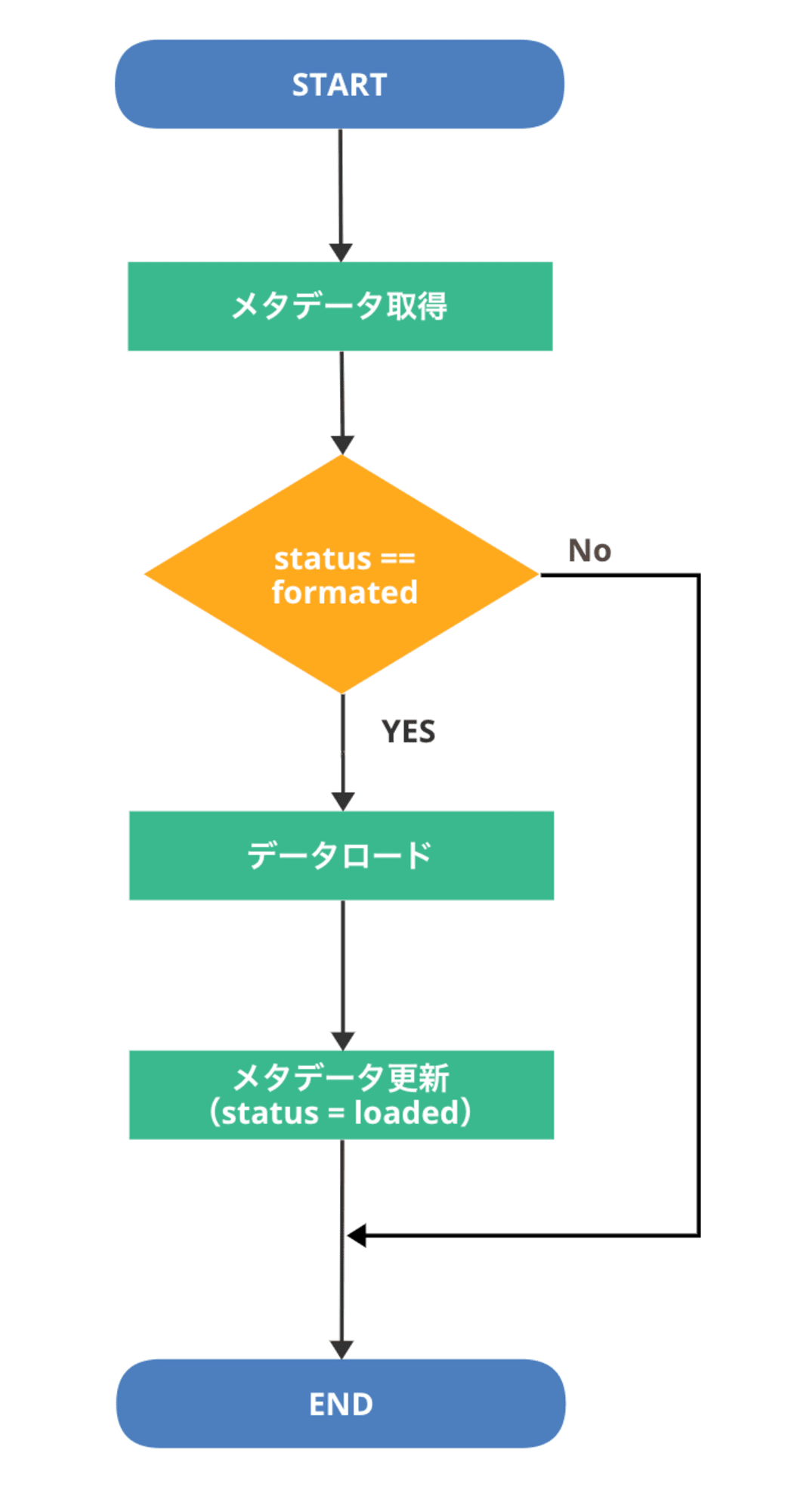
データロード処理
フォーマット変換処理同様、データロード処理でもまず対象ファイルのメタデータを取得して、
カスタムメタデータ status の値が formated であるかどうか確認します。
status が formated の場合はロード対象ファイルなので、ロード処理を実行します。
コードは以下の通りです。
from google.cloud import storage
def get_metadata(bucket_name, blob_name):
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(blob_name)
blob.reload()
print(blob.metadata)
return blob.metadata
def is_exec(bucket_name, blob_name):
metadata = get_metadata(bucket_name, blob_name)
status = metadata.get('status')
if status == 'formated':
return True
else:
print(f"invalid status: {status}")
return False
def set_blob_metadata(bucket_name, blob_name, metadata):
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(blob_name)
metageneration_match_precondition = None
metageneration_match_precondition = blob.metageneration
blob.metadata = metadata
blob.patch(if_metageneration_match=metageneration_match_precondition)
print(f"The metadata for the blob {blob.name} is {blob.metadata}")
def load_data(bucket_name, blob_name):
print(f"Exec load.")
def main():
bucket_name = 'test-mikami'
blob_name = 'export_data/path/file_test.csv'
# 実行判定
if not is_exec(bucket_name, blob_name):
return
# データロード処理実行
load_data(bucket_name, blob_name)
# メタデータ更新
metadata = {'status': 'loaded'}
set_blob_metadata(bucket_name, blob_name, metadata)
main()
フォーマット変換同様、実際にロード処理を実行するコードは省略して、ログ出力を行っています。
実行
フォーマット変換処理と、データロード処理それぞれの Python コードを順番に実行します。
$ python format.py
{'status': 'uploaded'}
Exec format.
The metadata for the blob export_data/path/file_test.csv is {'status': 'formated'}
$ python load.py
{'status': 'formated'}
Exec load.
The metadata for the blob export_data/path/file_test.csv is {'status': 'loaded'}
コード実行後の GCS ファイルのメタデータを確認してみます。
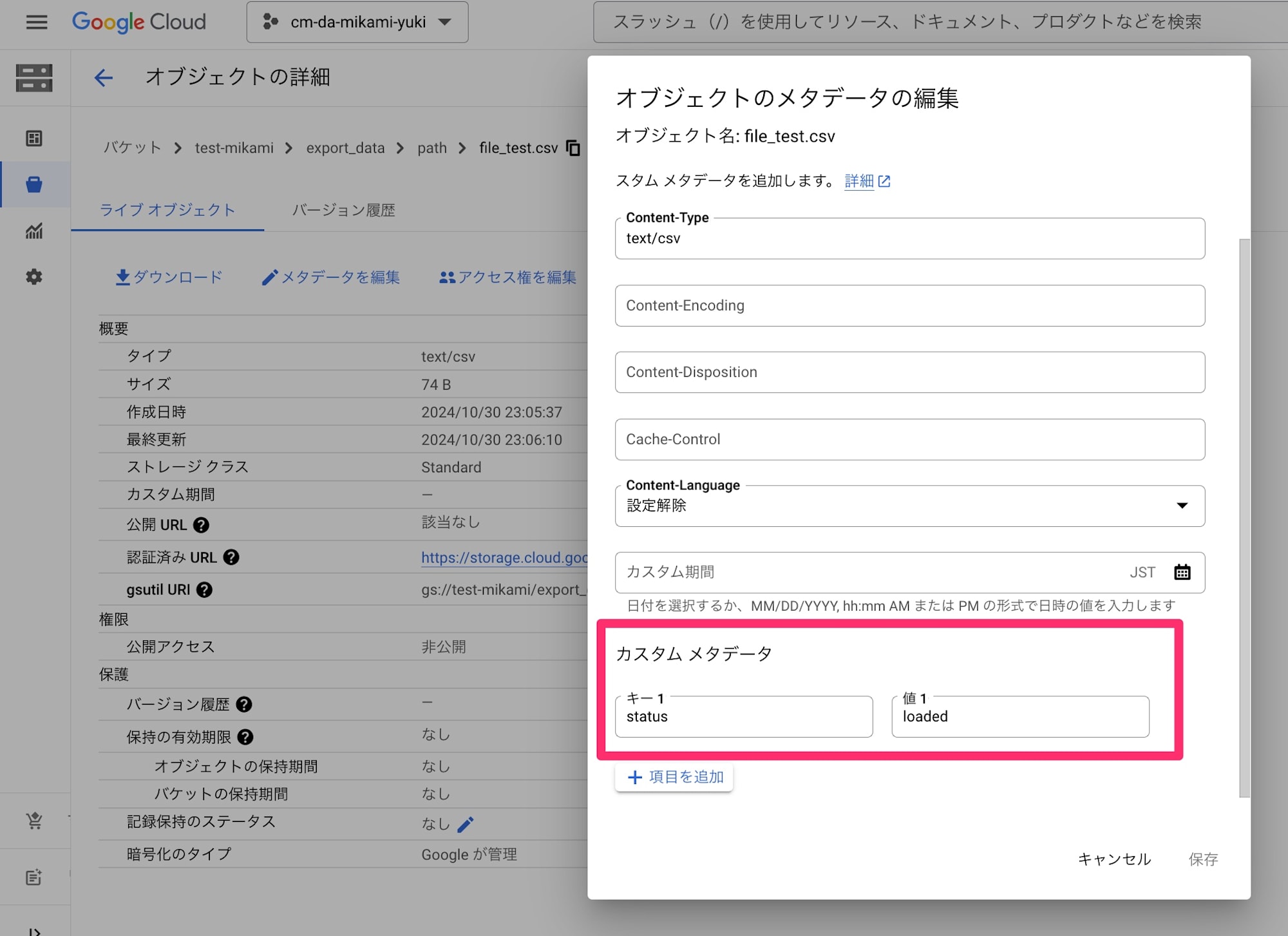
想定通り、GCS ファイルのメタデータを判定してそれぞれの処理を実行し、実行後にメタデータのステータスを更新することが確認できました。
もし、メタデータが期待するステータス値ではなかった場合の実行結果も確認してみます。
メタデータ status の値を error で更新して、再度 Python コードを実行してみます。
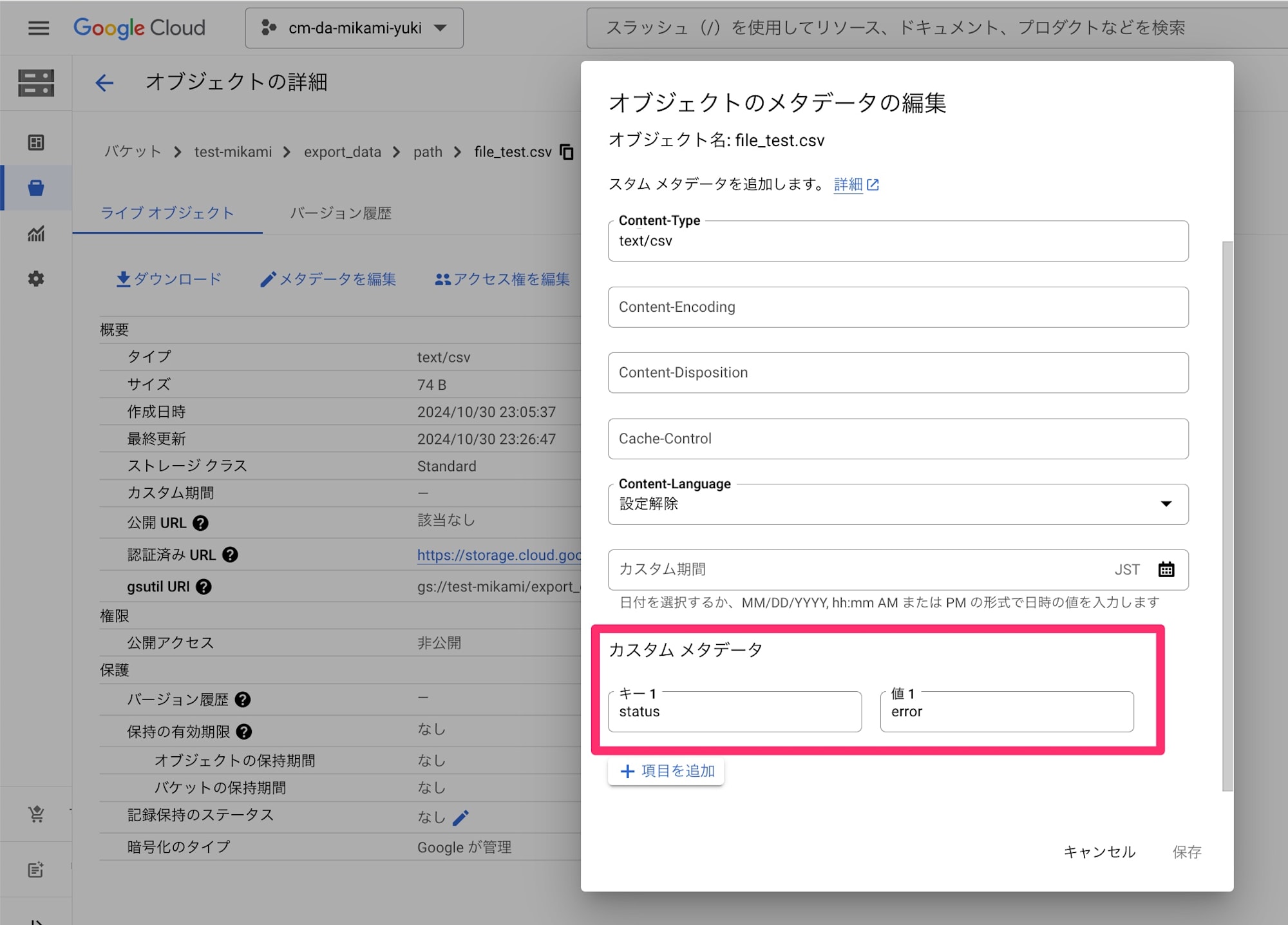
$ python format.py
{'status': 'error'}
invalid status: error
$ python load.py
{'status': 'error'}
invalid status: error
それぞれ、メタデータのステータスが期待値ではない場合は、想定通り実行判定で弾かれることが確認できました。
メタデータ更新イベントで Cloud Run Functions を起動してみる
GCS上のファイルメタデータが更新されたら Cloud Run Functions を起動するように、イベントトリガーを設定することも可能です。
例えば以下のように、データロード処理でエラーが発生した場合にのみ、エラー処理を実行したいケースを想定してみます。
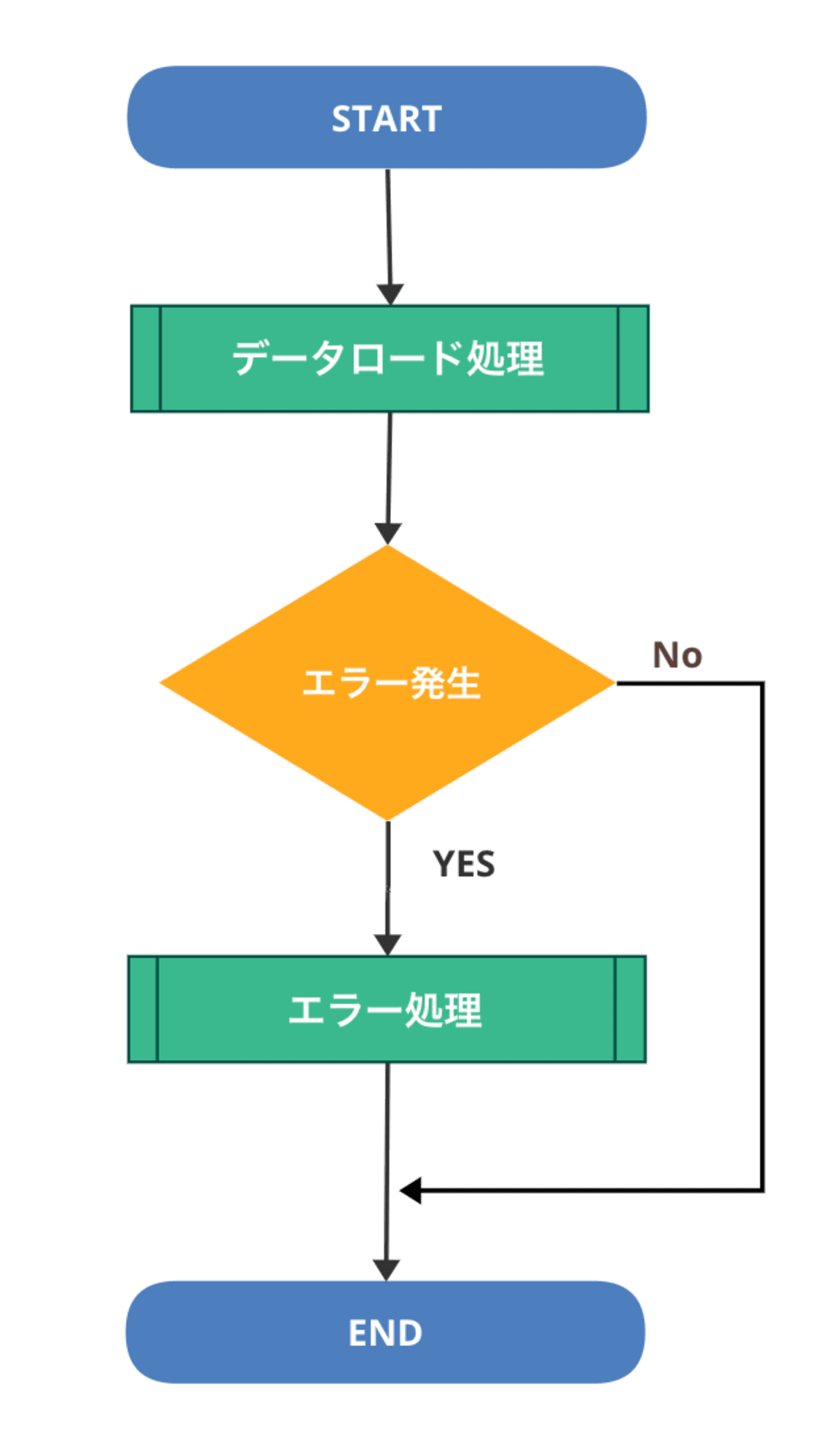
データロード処理の中では、エラー発生時のみメタデータの status を error で更新します。
エラー時にのみ、メタデータ更新トリガで起動する後続のエラー処理用の Cloud Run Functions が起動する想定です。
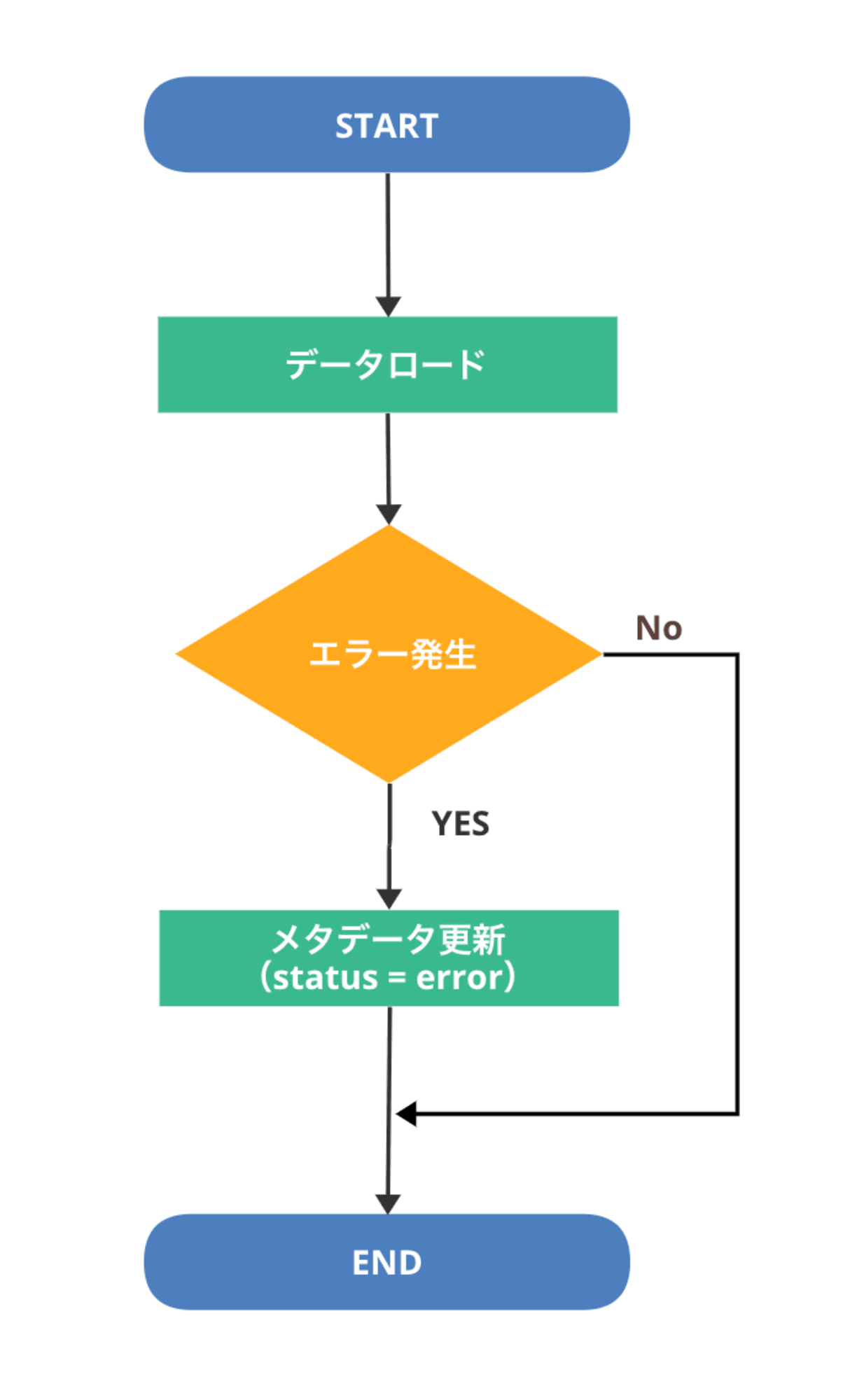
以下のデータロード処理の Python コードを用意しました。
from google.cloud import storage
def set_blob_metadata(bucket_name, blob_name, metadata):
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(blob_name)
metageneration_match_precondition = None
metageneration_match_precondition = blob.metageneration
blob.metadata = metadata
blob.patch(if_metageneration_match=metageneration_match_precondition)
print(f"The metadata for the blob {blob.name} is {blob.metadata}")
def load_data(bucket_name, blob_name):
# throw exception
raise Exception("for TEST.")
def main():
bucket_name = 'test-mikami'
blob_name = 'export_data/path/file_test.csv'
try:
# データロード処理実行
load_data(bucket_name, blob_name)
except Exception as e:
print(f"error: {e}")
# メタデータ更新
metadata = {'status': 'error'}
set_blob_metadata(bucket_name, blob_name, metadata)
main()
動作確認用なので、本来データロード処理を実行するサブ関数の中で Exception を raise します。
メイン関数で Exception を Catch した場合は、メタデータの status を error で更新します。
メタデータ更新イベントをトリガに実行する、以下の Cloud Run Funcrions をデプロイします。
from google.cloud import storage
import functions_framework
def get_metadata_status(bucket_name, blob_name):
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(blob_name)
blob.reload()
print(blob.metadata)
metadata = blob.metadata
return metadata.get('status')
def error_handler(bucket_name, blob_name):
print(f"Exec Error Handling.")
@functions_framework.cloud_event
def main(cloud_event):
data = cloud_event.data
bucket_name = data["bucket"]
blob_name = data["name"]
# メタデータ取得
status = get_metadata_status(bucket_name, blob_name)
if status != 'error':
print(f"status: {status}")
return
# エラー処理実行
error_handler(bucket_name, blob_name)
google-cloud-storage>=2.18.2
functions-framework==3.*
以下の CLI コマンドでデプロイしました。
gcloud functions deploy error_handler_trigger_metadata_update \
--runtime python312 \
--trigger-event google.storage.object.metadataUpdate \
--trigger-resource test-mikami \
--entry-point main \
--region asia-northeast1
load_error.py を実行して、メタデータの status を error で更新してみます。
$ python load_error.py
error: for TEST.
The metadata for the blob export_data/path/file_test.csv is {'status': 'error'}
メタデータ更新で Cloud Run Functions が実行されたか、ログを確認してみます。

想定通り、メタデータ更新イベントで Cloud Run Functions が実行されることが確認できました。
ねんのため、メタデータのステータスが error ではなかった場合の挙動も確認してみます。

エラー処理関数では初めにメタデータステータス値のチェックを行っているため、error ステータス以外の場合は処理実行しないことが確認できました。
なお、もしメタデータ更新トリガを使用する場合は、本来の目的以外で GCS オブジェクトのメタデータが更新されるケースがないか、または本来の目的とは異なるタイミングで Functions が起動しても問題ないか、十分ご検討ください。
処理ステータスでファイルをフィルタリング
例えばエラーのファイルを確認する場合など、指定したメタデータを持つファイルを CLI で検索することも可能です。
以下の Bash スクリプトで、メタデータの status 値が error のファイルを検索してみます。
検索対象のバケットとパス(ディレクトリ)は、スクリプト実行時の引数で指定します。
#!/bin/bash
# 引数チェック
if [ "$#" -ne 2 ]; then
echo "Usage: $0 BUCKET_NAME PREFIX"
exit 1
fi
BUCKET_NAME="$1"
PREFIX="$2"
METADATA_KEY="status"
METADATA_VALUE="error"
# オブジェクトリスト取得
gcloud storage ls --recursive "gs://$BUCKET_NAME/$PREFIX" | while read -r obj; do
# ファイルではないので処理しない
if [[ "$obj" == */: ]]; then
continue
fi
# メタデータ取得
metadata=$(gcloud storage objects describe "$obj" --format=json 2>&1)
# エラーチェック
if echo "$metadata" | grep -q "ERROR"; then
continue
fi
# カスタムメタデータチェック
status_value=$(echo "$metadata" | jq -r --arg key "$METADATA_KEY" '.custom_fields[$key]')
if [ "$status_value" == "$METADATA_VALUE" ]; then
# statusがerrorのオブジェクトをprint
echo "$obj"
fi
done
実行結果は以下です。
$ bash check_error_files.sh test-mikami export_data/path
gs://test-mikami/export_data/path/file_test.csv
メタデータのステータスが error のファイルが検索できました。
まとめ(所感)
ファイルのメタデータでバッチ処理ステータスを管理できることが確認できました。
GCS ファイルのカスタムメタデータを使えば、key-value 形式で好きな値を付与できるので、ステータス管理以外にも、データ種別や処理種別、ファイルのバージョン管理など、用途に合わせて様々な情報を付与することが可能です。
処理対象ファイルをファイルパスやファイル名で判断できない制約があったり、ファイルごとに処理内容を分岐したいけれども管理用の別ファイルやデータベースなどを作成したくない場合など、カスタムメタデータを使えば処理の幅も広がるのではないかと思いました。









